ABAP
职场和发展
编码
solidity
智能合约
android studio
devops
自定义Toast
STM32G070RBT6
YoloV5
技术美术
gcc
引用
测试开发
java8新特性
springboot
界面设计
网络管理
MMoE
图片提取
反爬
2024/4/11 23:34:54
你知道吗?python lxml 库也能用于操作 svg 图片
在大多数场景中,我们都用 lxml 库解析网页源码,但你是否知道,lxml 库也是可以操作 svg 图片的。我们可以使用 lxml 中的 etree 模块来解析 SVG 文件,然后使用 SVG 中的各种元素和属性来进行操作。 python lxml 库操作 svg 图片lxm…
盘点数据采集中14种常见的反爬策略
引言
随着互联网的飞速发展, 爬虫技术不断演进, 为数据获取和信息处理提供了强大支持。然而, 滥用爬虫和恶意爬取数据的行为日益增多, 引发了反爬虫技术的兴起。在这场看似永无止境的 技术较量 中, 爬虫与反爬虫技术相互博弈、角力。本文将简单过下目前已知的几种反爬策略, 旨…
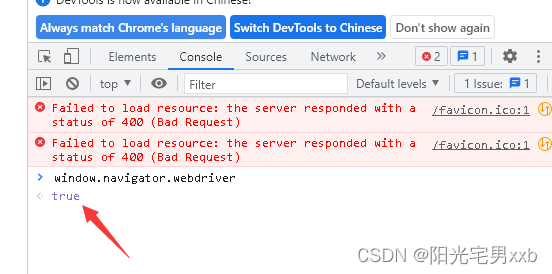
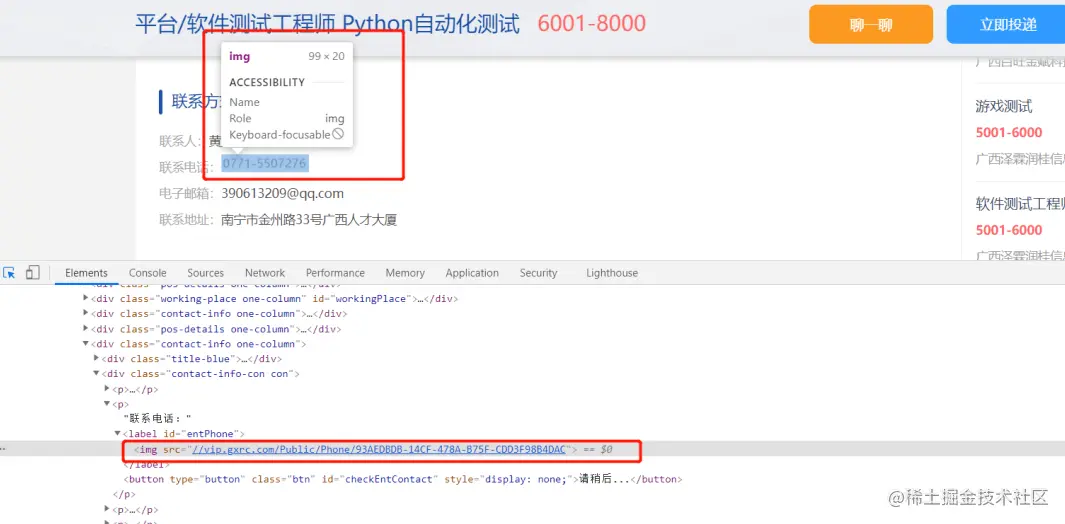
【已解决】使用selenium启动谷歌Chrome浏览器打开指定网站,页面空白,而使用其它浏览器手动打开该网站则正常
问题描述
1、在使用python实现自动化网络爬虫时,我使用到selenium来驱动谷歌Chrome浏览器来打开某一个网页,然后爬取数据,代码如下: from selenium import webdriver
import timedriver webdriver.Chrome()
driver.get(https://…

(已解决)关键词爬取百度搜索结果,返回百度安全验证,网络不给力,请稍后重试,无法请求到正确数据的问题
已解决,使用关键词进行百度搜索,然后爬取搜索结果,请求数据后,返回的是百度安全验证,网络不给力,请稍后重试。无法请求到正确数据。且尝试在header中增加Accept参数还是不行。 一、问题产生的现象 在学习过…